
Only this way, customers COULD be able to reveal the true power of all the available information. There’s no need to say it takes quite some effort for the organization to get all data into the data lake. But when everything is in place eventually, the real question pops up: “So I’ve got a great data lake, now what?…."
"But when everything is in place eventually, the real question pops up: “So I’ve got a great data lake, now what?…."
Teams start to write queries to produce reports they need. Usually, this is very time consuming since the model used by most data lakes is based on flat tables or indexes. With the necessity for correlation between different data sources (different tables), joins need to be created. The written queries are perfectly suited for reproduction, so once in place, they can be used for generating reports periodically (like SLA reports, website usage, and availability reports). However, how could you get more value out of your data lake?
Imagine you could use this wealth of data to be able to answer ad-hoc questions from the business? Like: “Show me all components that are not related to an end-user”, “I need to know NOW what business processes depend on a certain IT component” or “What was the root cause of the performance issue our customers experienced two hours ago?”. Then the model of the data lake doesn’t really help…
What would help in these cases, is having a model that has an understanding of how components are related to each other. A model that would give insight into how the stack is being built up. A model that also correlates all additional relevant information (like monitoring data, change & config data and service management data) automatically to these components and their relations. Then you will be able to answer the above mentioned ad-hoc questions. And a lot more…
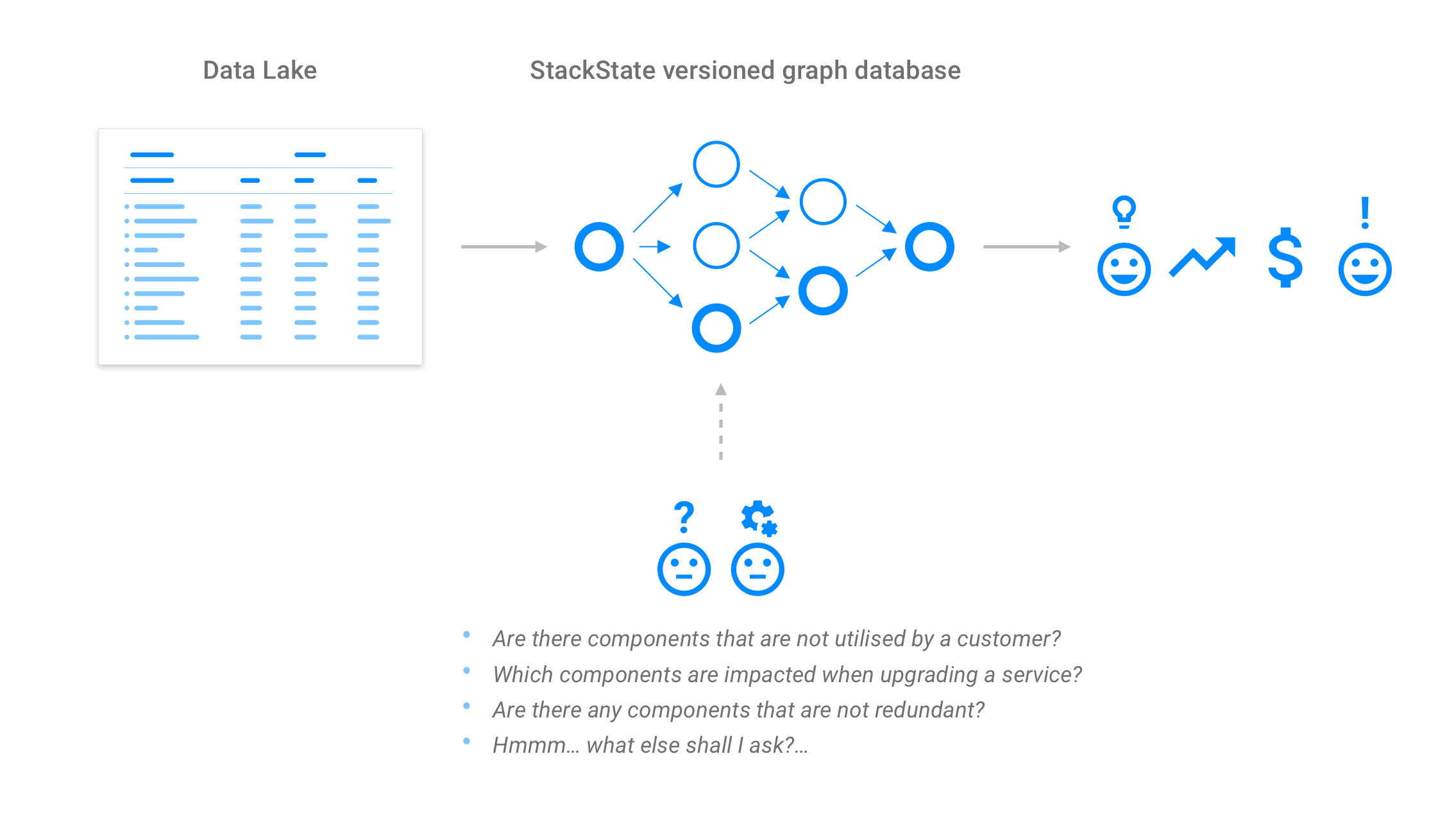
StackState has created an Algorithmic IT Operations (AIOps) platform that uses such a model. StackState’s unique 3T model is built on a versioned graph database, which allows you to reason over the graph. It combines topology, telemetry and time in one unified view. It can retrieve data not only from your data lake, but from any other data source that has not been connected to your data lake (like network data for example. This usually is such a large amount of data, it will cause the license costs of your data lake to explode when getting this data in).
By getting the information and applying the 3T model to it, StackState will add a lot of extra value to your investments already made in your data lake. As a decentralized solution, StackState can be used by any team to get the most value out of the data that is relevant to their jobs.
"Thus, the question “So I’ve got a great data lake, now what?” will be answered by StackState."
Thus, the question “So I’ve got a great data lake, now what?” will be answered by StackState. Imagine you have a system that fully understands your complete IT landscape, from business processes to hardware, from legacy to microservices… The data is there, it only has to be revealed. Then the possibilities seem endless…
In my next blog, I will elaborate about how StackState’s 3T model will drastically enhance your root cause analytics capabilities. If you would like to try StackState, you can access our live demo environment right here, anytime !


