4 types of data to train ML models
Clients often ask us: what kind of data do we need to take advantage of AIOps? Do we have enough data? Should we invest in data and how can we do that? StackState uses 4 types of data to train its ML models:
Unsupervised data
Weakly/semi-supervised data
Supervised data
Reinforcement learning data
The image below illustrates the kinds of data in a pyramid, where each layer represents the abundance of each data type. Unsupervised data is available in large quantities, where as reinforcement learning data is extremely scarce. The fact that StackState exploits all four data types to the fullest, enables it to deliver value to the client fast without much investment by the client.
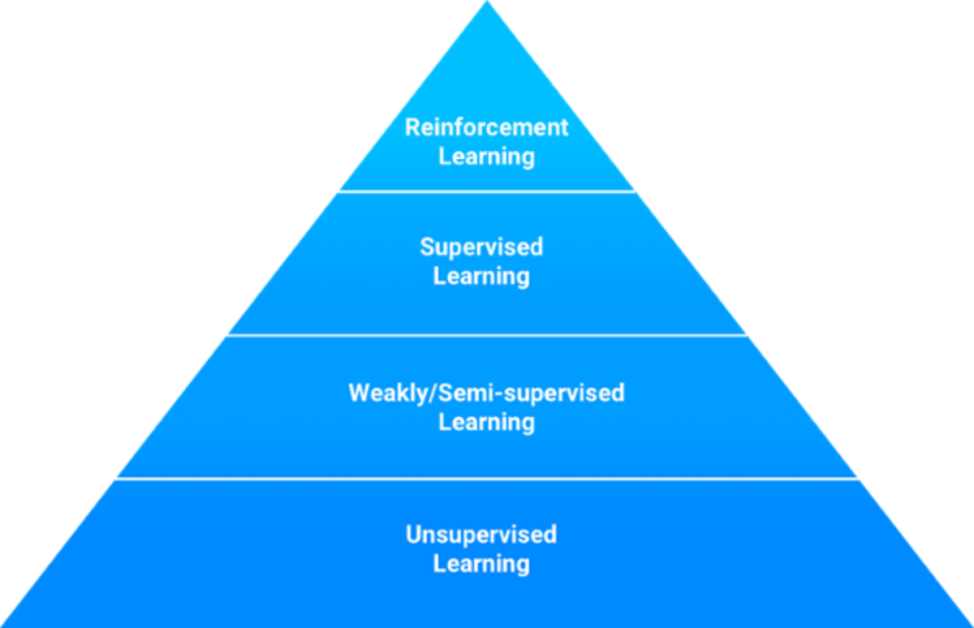
System layer vs. task layer
What are these different types of data? Where do they come from? And what can you learn from them? The data pyramid can be divided into two super-layers: the system and the task layer. The system layer is formed by the weakly/semi-supervised and unsupervised data. Reinforcement learning data and supervised data together form the task layer.
The system layer
In the system layer the machine learning models learn how the IT environment behaves, what is the dynamics within a component and between related components. The data in this layer comes from observed IT system behaviour – the data is the system logs, metrics, infrastructure events such as deployments, health state changes and other signals that can be collected automatically without human interactions. The key here is automatically and without human interactions. This makes the data very abundant – as the system exists it produces vast quantities of information.
The difference between unsupervised learning and weakly/semi-supervised learning
Unsupervised learning models the system behaviour while weakly/semi-supervised learning learns about relationships between components of the system. Unsupervised learning answers the question what will happen next in general. Weakly/semi-supervised learning answers specific questions like will there be a component update, when will the health state change, will there be a burst in traffic, will there be a drop in error rates. Learning to answer these questions is equivalent to understanding the IT system.
What can be learned from this data? Many things! As a matter of fact, we can learn most of the things just from this data. We can learn how the system behaves, how different components of the system affect each other, what are the usual sequences of events, what happens before a health state of a components changes, how these changes propagate through the topology, how different telemetry streams are related, how often they change their behaviour and how these changes propagate and so on. One could say that before performing unsupervised and weakly/semi-supervised learning the machine learning model is like a rookie who knows nothing of IT. After unsupervised and weakly/semi-supervised learning the model is like a seasoned IT operator with the understanding of the particular IT system ready to solve any tasks.
The task layer
In the task layer we tell the machine learning models what tasks we want to solve in particular. In the previous layer the model has gained general knowledge required to solve any IT related task, but it does not know which task it needs to solve. In this layer the model needs an input from human operators and task specific data.
At StackState we want our machine learning models to predict failures, detect anomalies and find the root cause – these are some of the most important tasks for our clients. For each of these tasks we need some data to tune our models. For example, for failure prediction we need some examples of failures, and for anomaly detection we need some past anomalies. The goal of the learning in the layer is to learn which IT events are bad for your business.
Where can you get this data? In supervised learning the main source of this data are the post-mortem reports – by looking at them the model can learn what kind of system behaviour is considered problematic. It is important to remember here that the model already knows what is each components dynamics, how the components affect each other, how the system behaves and how to forecast its behaviour due to unsupervised and weakly/semi-supervised learning – now the model only need to learn to separate “good” from “bad”. Because the model already has rich knowledge of the system it does not need many post-mortems.
The final learning step is reinforcement learning, here the model learns the most specific knowledge, namely what the human operator really wants it to do. Each human is different – some of us are more frustrated by alerts than others, some prefer to be given long and exhaustive reports, some like the system to be more proactive, some like to be in charge. In reinforcement learning the model adapts itself to the human operator and learns from his or her feedback. The feedback can be given explicit or implicit. Explicit feedback is given when the operator tells the model things as "do not show me this again", or "do it more often". Implicit feedback is given when the user ignores alerts, or the opposite – the user pushes changes to the component flagged by the model. This implicit and explicit feedback closes the loop between the model and the user – the model learns exactly what the user wants it to do.
StackState data strategy
StackState's data strategy is composed of the two layers I just explained – the system and the task layer. In the system layer the models learn how the client’s IT system operates, what to expect from it, how the different components affect each other and how different metrics correlate. In the task layer the model learns how to solve particular tasks – predict failures, detect anomalies and perform root cause analysis. In the first layer the model already became proficient at the particular IT system and in the second layer it just needs to learn what is “good” and what is “bad”. Finally, as a cherry on top, the model also learns what a particular human operator wants from it. In this way StackState provides exactly the experience our client needs.


