
Imagine a symphony where every musician plays their part flawlessly, but without a conductor to guide the orchestra, the result is just a discordant mess. Now apply that image to the modern IT landscape, where development and operations teams work with remarkable autonomy, each expertly playing their part.
Agile methodologies and DevOps practices have empowered teams to build and manage their services independently, resulting in an environment that accelerates innovation and development. However, this shift towards team autonomy and responsibility presents a significant challenge at the same time: maintaining a unified view of an organization's entire IT operations.
Two Sides Of The Observability Story
When each team focuses on its own set of services, the broader perspective of how IT Operations interconnect and support overarching business goals can become blurred. It's as if each section of the orchestra is simultaneously playing a different tune.
The crux of the matter lies in finding the balance between autonomous action and a unified end-to-end observability approach . There is a pressing need for an observability strategy that not only respects the independence of each team but also weaves their efforts into a coherent narrative that monitors overall business reliability.
The Challenges of Decentralization
The transition from centralized IT monitoring to autonomous, cross-functional teams taking care of their own observability is a major shift in software development and system operations. Gone are the days when a single team oversaw the entire IT landscape, with every alert and issue funneling through a central command center.
Today, teams are structured around specific services or products, each equipped with their own tools and processes to monitor, update, and maintain their corner of the application and infrastructure. They’re the owners of their features, responsible for their success from creation to retirement.
The empowerment that comes from this shift is glaringly apparent. Agile practices have given a sense of accountability, a responsibility that’s further embedded through CI/CD pipelines — the lifelines of delivery — which allow teams to confidently introduce changes, knowing that they can deploy, test, and roll back as needed. That, in turn, allows businesses to push out features at a speed previously unimaginable, reacting to market demands and user feedback with agility and precision.
Decentralization, however, introduces a challenge in maintaining comprehensive system-wide visibility and can turn an entire IT environment into a patchwork of disparate applications. And that's the real challenge: ensuring that a team's autonomy doesn't jeopardize the unified view required for the organization's overall success.
Roles and Responsibilities in Modern IT Operations
In today's IT setups, many roles play a part in launching new applications. It's crucial to keep these roles connected and aligned with the same objectives. Let’s look at some common functions.
Business Owners outline the vision and objectives guiding IT delivery. Their strategic goals shape the direction of future IT implementations.
Network Operation Centers (NOCs) oversee the entire landscape, with some of their responsibilities now taken on by application development teams.
Application Custodians/Owners ensure each application is secure, compliant, and functions according to specifications.
Development Teams drive development and operations.
Platform Teams build and maintain the infrastructure platforms for developers to deploy on.
Each of the above roles is instrumental in ensuring the system's purpose and health, but they can’t do it alone. The magic happens when they collaborate, with individual notes fitting into a larger arrangement, much like the orchestra at the beginning of the article. Without a conductor — a comprehensive strategy considering all roles — silos form. Information becomes as compartmentalized as the roles, with each team working in isolation, aware of their own part but oblivious to the overall symphony.
As you can see, it's not enough for each section to know its part; they must also understand how they fit into the broader piece. That’s where observability comes in.
The Critical Contribution of End-to-End Observability
In IT Operations, observability is like high-definition vision. Beyond just seeing when and where things happen, observability helps us understand why something happens. Unlike traditional monitoring, it provides a three-dimensional view of system and service performance. This deeper insight is pivotal for business stakeholders, as it directly influences business reliability. Observability brings three key benefits that can significantly impact a business.
Proactive Issue Resolution: With end-to-end observability, businesses can anticipate problems before they affect customers. With a strong focus on reducing MTTR, the blast radius of any issues can be kept to a minimum.
Informed Decision Making: Troubleshooting goes beyond understanding technical glitches; it's about grasping the business impact. Having that end-to-end picture helps guide focus to the critical areas that need attention.
Customer Experience: A clear view of the system's health facilitates swift improvements to user interfaces and functionalities, giving customer satisfaction a boost and fostering loyalty and positive brand perception.
End-to-end observability empowers stakeholders not just to react to incidents but to predict and prevent them. It aligns IT performance with business goals in a way traditional monitoring systems can't. This proactive approach is crucial in a world where customer satisfaction is as unpredictable as the technology that supports it.
Goal Setting: SLIs, SLOs, and SLAs
When it comes to IT Operations, it makes no sense to jump in headfirst without clear and measurable goals to steer performance in the right direction. This is where the goal-setting framework of Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Service Level Agreements (SLAs) comes into play.
Service Level Indicators (SLIs): At a granular level, SLIs are specific, measurable metrics offering real-time data on the health of various IT components. For example, an SLI might measure the response time of a service or the error rate of an application. These indicators are the pulse points monitored by autonomous teams to ensure optimal functionality within their respective areas.
Service Level Objectives (SLOs): Moving up a level, SLOs represent the targets set for SLIs. Aligned with broader business objectives, SLOs establish performance goals for application teams. An SLO could, for instance, aim to maintain a 99.9% uptime for a critical application. These objectives ensure that individual team efforts contribute to the overall reliability and effectiveness of the system.
Service Level Agreements (SLAs): At the highest level, SLAs are formal commitments made to business stakeholders, including external clients. They encapsulate the expectations set in SLOs and guarantee a specific level of service based on SLIs. For example, an SLA might promise a certain level of system availability or response time to customers. These agreements directly link the operational achievements of IT teams to business outcomes and customer satisfaction.
By establishing SLIs at the component level, setting SLOs at the team level, and aligning them with SLAs at the business level, organizations create a cohesive and accountable framework.
This structured approach ensures that the success of autonomous teams goes beyond isolated achievements and is directly tied to the strategic objectives and commitments of the business. It facilitates a powerful connection between autonomous engineering teams, end-to-end observability, and business needs.
StackState: Elevating Observability to New Heights
The key question that lingers is how to integrate business goals and IT objectives into a unified observability strategy. Essentially, how can these two worlds be seamlessly merged? If this integration is a crucial tool for any modern enterprise, how does one go about implementing it?
At StackState, making this integration happen has been an integral part of our mission and our understanding of complex IT environments right from day one.
Consider the image of the connected layers below, where each layer, from resources at the bottom to the business offering at the top, depends on the layer below. StackState embodies this concept by collating data across these layers, providing insights that are both deep and broad. We stitch together the fine-grained metrics at the component level (SLIs) with the overarching business goals (SLAs), giving a real-time, end-to-end view of the system's health.
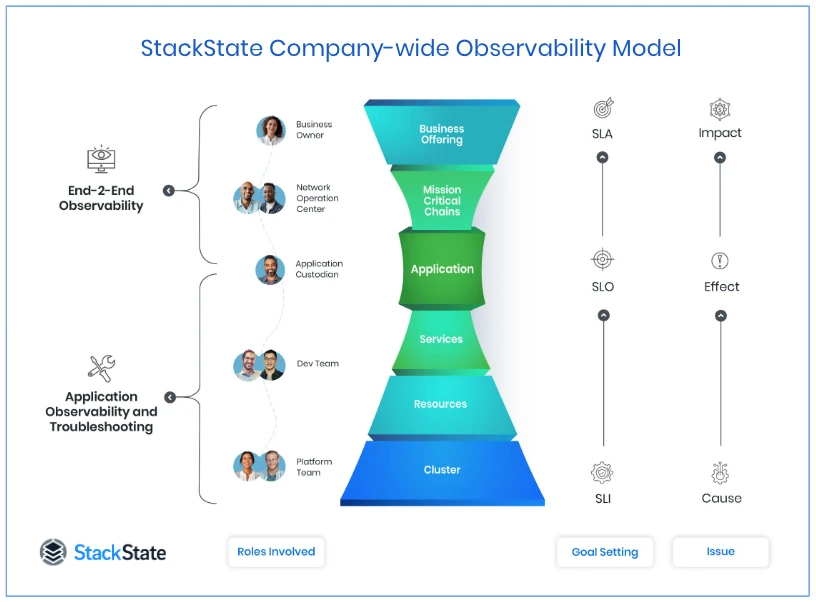
StackState offers a full stack observability platform that brings the needs of autonomous teams together with the holistic picture of the business. And we do that by understanding that it's not about raw data, it's about transforming that data into a narrative that makes sense for each layer — from platform teams to business owners.
IT Operations: For autonomous teams, StackState provides immediate out-of-the-box value. Tailored for those looking to build robust observability practices within their domains, it offers intuitive interfaces, detects over 30 common issues, and provides numerous remediation playbooks for quick issue resolution. This allows teams to hit the ground running as they can start extracting insights and optimizing performance in less than 5 minutes.
Business Owners: StackState's true strength lies in its ability to offer a unified perspective. It provides a single intuitive view and easy-to-navigate interface across the entire IT landscape. This unique capability is a game-changer for network operation centers and business owners alike. By integrating data from various sources — including team observability data and the rich repository of Splunk's data layer — StackState breaks down the silos of data and can pinpoint potential and current issues straight away.
We initiated this article on end-to-end observability with the metaphor of a discordant symphony. If there's one takeaway from this piece, let it be this: With StackState, decision-makers can anticipate and address issues before they escalate, ensuring that their IT orchestra plays harmoniously with the tempo set by the business's maestro conductor. Bravissimo!
How will observability play out with your teams?
To find out, have your IT team try it out in the StackState playground . Or, to understand how end-to-end observability will strengthen any mission-critical application chain in your enterprise, book a demo with us.


