
In the complex and fast-paced world of application deployment, getting a handle on the tangle of services and resources can sometimes feel like trying to find your way through a maze without a map. And if something goes wrong, trying to find out what's happening where is even more difficult. With alert emails flooding in and questions flying left and right, identifying the glitch that's causing issues can seem like a Herculean feat.
This is where root cause analysis and application dependency maps, the unsung heroes that simplify troubleshooting, emerge as secret weapons. They automatically detect and showcase service dependencies, clearly showing the intricate relationships between various components.
With dependency maps, you can effortlessly track resource changes, keep a vigilant eye on app performance, and quickly pinpoint the root cause of any issue — way quicker than you could manage if tackling all those steps manually. This means faster issue resolution and smoother operations overall.
In this blog, I'm going to reveal how dependency maps transform the daunting task of troubleshooting by quickly finding the root cause of an issue at hand and turning what once felt overwhelming into a much more straightforward process.
Simplifying Troubleshooting with Application Dependency Maps
Application dependency maps serve as a visual roadmap, illustrating the complex interactions among components within your environment. With StackState, the intricacy is simplified, allowing developers, SREs, and platform teams to quickly identify and address the root causes of problems that can slow down or stall your internal and customer-facing applications.
Our advanced mapping goes beneath what's visible on the surface, revealing hidden layers and weak links to help diagnose issues and optimize performance effectively.
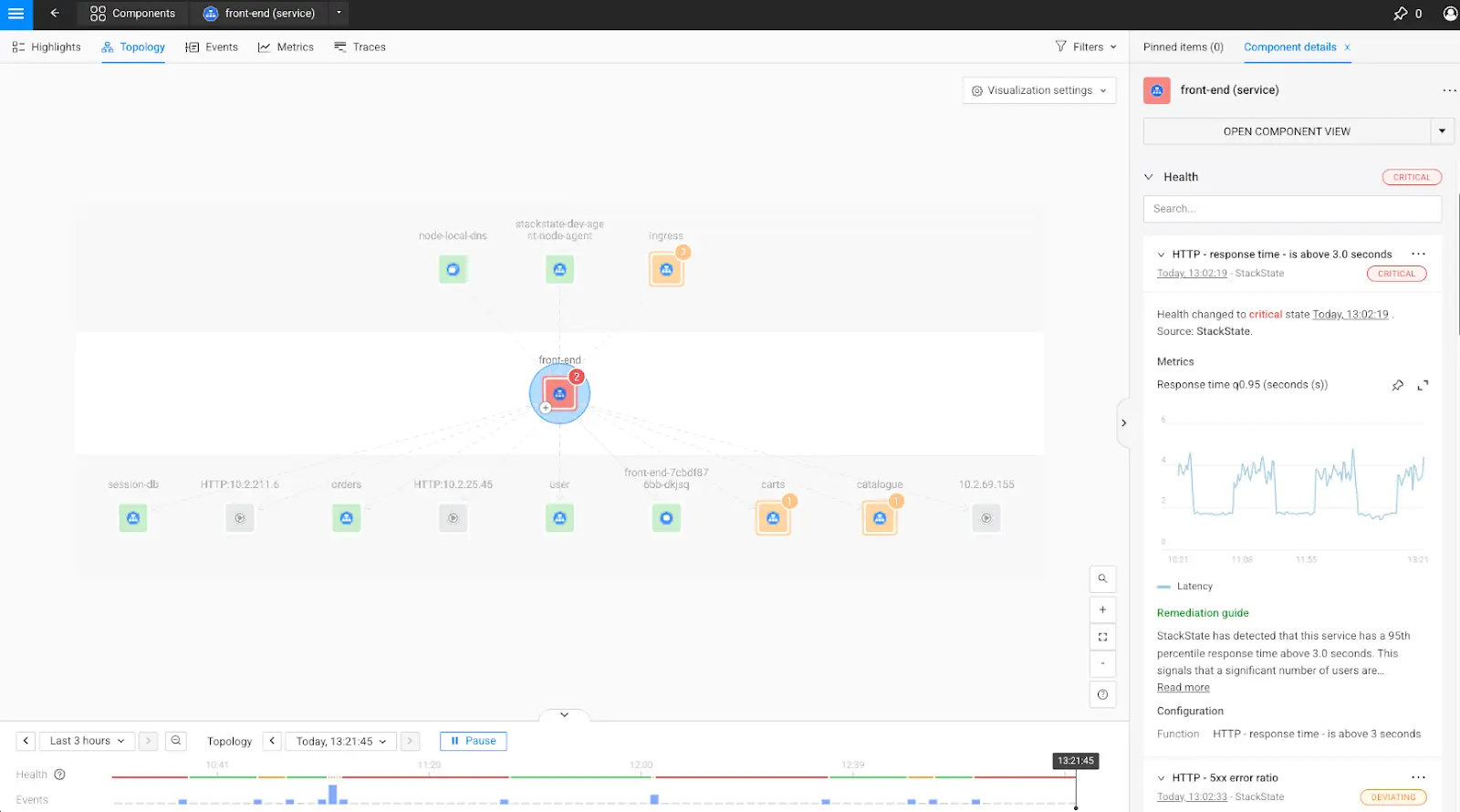
Benefits of application dependency maps:
Broad Visualization of Complex Systems: Dependency maps provide a visual representation of the intricate relationships throughout your entire ecosystem. This deeper dive includes dependencies that may not be immediately apparent and helps teams better understand how different parts of the ecosystem interact.
Rapid Problem Solving: With dependency maps, teams can more easily detect and resolve issues, which in turn minimizes downtime and improves overall system reliability. And since StackState's root cause analysis integrates system health information, your teams keep the focus on innovation. Faster troubleshooting allows for more time to concentrate on developing new features.
Direct Impact Analysis: Dependency maps allow teams to trace the impact of an issue across the system, identify bottlenecks and optimize performance more effectively. By visualizing dependencies, developers and engineers can pinpoint areas of the system that require optimization and prioritize improvements based on the severity and importance of affected components.
Knowledge Accessibility: Dependency maps in StackState act as a centralized hub for developers, SREs, and platform engineers, fostering collaboration and collective problem-solving. By making troubleshooting accessible to team members of varying expertise levels, StackState ensures a shared understanding of system architecture, serving as a "single source of truth" and mitigating company-wide fire drills.
Quick Onboarding: Dependency maps provide a clear and intuitive overview of the application architecture and can help new team members quickly grasp the complexities of your entire ecosystem. This can streamline and accelerate the onboarding process for new team members by helping them understand the relationships between different components and which teams within the organizations are responsible for their support.
Data-Driven Diagnosis: By integrating telemetry data into dependency maps, teams can access detailed insights into individual components' health and performance, leading to more accurate diagnoses of issues and more informed decision-making. Additionally, by continuously monitoring application dependencies, teams can proactively anticipate potential problems and implement preventive measures, ensuring the stability and reliability of the application environment.
Complete Ecosystem Understanding: Dependency maps go beyond simple direct dependencies, allowing teams to visualize direct — and indirect — relationships and dependencies that may not be immediately obvious. By extending mapping to include external APIs, databases, or queues observed in calls from your applications, StackState enables a deeper, holistic view of the entire ecosystem, making it a more comprehensive observability solution.
Embracing Best Practices
StackState champions best practices in monitoring and management, enhancing the reliability and efficiency of your environment. Our observability approach goes beyond root cause analysis to offer guidance on managing complex cloud-native applications and microservices crucial to your business's success.
By combining best practices with pre-configured out-of-the-box monitoring and our distinctive troubleshooting intelligence, the StackState full stack observability platform preemptively identifies correlated issues and provides guidance on resolving them before they escalate.
This proactive approach, embedded in our solution, reduces the likelihood of undetected problems and promotes the maintenance of a robust IT environment. With StackState, your operations are on a proven path to better reliability.
Advancing with Assisted Remediation
StackState's standout feature, assisted remediation, leverages out-of-the-box monitors that keep a close eye on all critical signals. This feature is a game-changer, significantly impacting the time it takes to find and fix issues by reducing the Mean Time To Detect (MTTD) and the Mean Time To Resolve (MTTR) those problems.
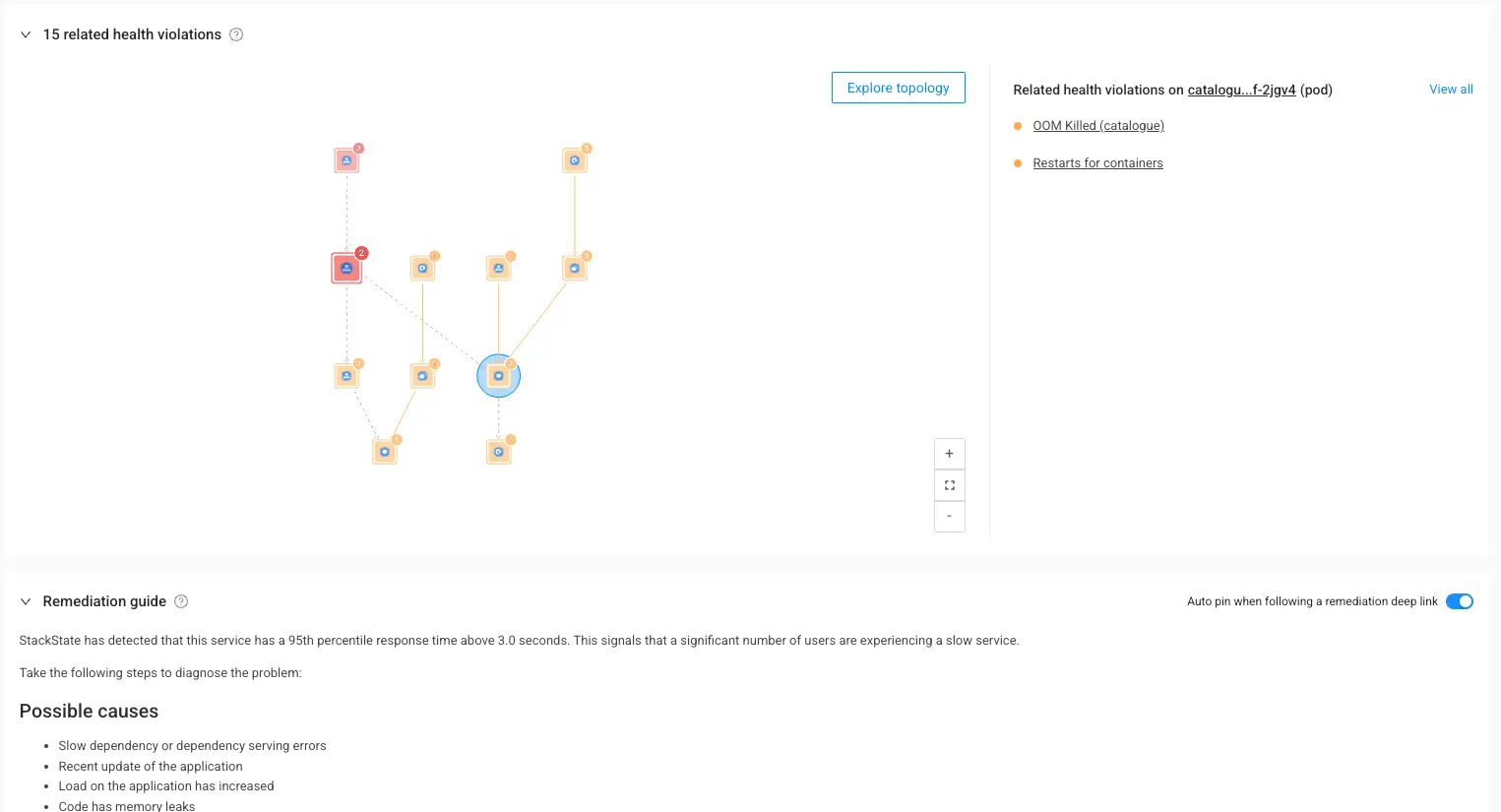
How Remediation Works:
Proactive Alerts: Get timely notifications via your preferred channels such as PagerDuty, OpsGenie, Slack, or any other system. Each alert comes packed with comprehensive issue details and potential causes, keeping you informed and ready to take action.
Guided Investigation: Every alert includes a direct link to the ongoing incident and provides:
Clear Evidence: Detailed analytics on the issue at hand.
Step-by-Step Resolution: Tailored instructions for remediation.
Impact Analysis Map: A visualization of related health violations allows you to tackle root causes more effectively, steering clear of the "red herring" effect — where less relevant information distracts attention and leads to superficial fixes. By automatically directing you to the real problem, our solution ensures you don't waste time chasing down troubled resources that may not be the actual source of the issue.
Fast Resolution: By seamlessly integrating out of the box monitoring with instant alert and proven, guided remediation, all problems — large or small — within your environment are promptly detected and addressed.
StackState's Edge in Troubleshooting
StackState's approach to assisted remediation transcends mere feature functionality; it's a holistic strategy ensuring the health and performance of your deployments. Unlike other observability providers, detecting the root cause of application issues isn't our end goal; it's our jumping-off point!
Once the root cause is pinpointed, our dependency maps empower you to take immediate action. With 360-degree views and deep dive functionality, we transform raw data into actionable insights and even walk you through remediation step-by-step. Even the most intricate ecosystems become easy-to-understand maps. It's like having Waze for your applications!
Driven by deep eBPF-based integration, our solution offers zero-configuration deployment, ensuring seamless integration with your existing cluster architecture. And while it's incredibly simple to deploy, StackState doesn't compromise on functionality; it's engineered to deliver robust results. With application dependency mapping and data-driven insights, our root cause analysis capabilities are designed for ease of use and depth of detail, distinguishing us in a competitive landscape.
A New Era of Operational Excellence
Let's face it: things are moving fast in today's technology landscape, and every day, your teams face the daunting task of managing and troubleshooting complex systems. Whether it's Kubernetes troubleshooting or any other environment, pinpointing the root cause of issues in a tsunami of alerts and notifications can feel like finding a needle in a very wet haystack.
Combined, our round-the-clock monitoring, application dependency mapping, intensive analyses, and assisted remediation become a powerful toolkit, transforming the troubleshooting process into a straightforward and manageable task. Together, they empower teams — your teams — to focus on growth and innovation by streamlining the problem-solving process.
We invite you to take a closer look into the world of full-stack observability by exploring the StackState playground and unlocking a new dimension of application management. Visit the StackState Playground now!


